El Departamento de Investigaciones Lingüísticas y Filológicas inició durante el año 2016 una colaboración con el Laboratorio de Inteligencia Artificial Aplicada, dependiente del Departamento de Computación de la Universidad de Buenos Aires, para desarrollar tecnologías de detección de léxico con contrastes de uso dentro del territorio de la Argentina. Por razones de accesibilidad, consistencia y la disponibilidad de información geográfica, la fuente de información que se está usando es la red social Twitter. En la primera etapa, se recolectaron más de 188 millones de palabras divididas en partes aproximadamente iguales por cada provincia del país. Más allá de ciertos problemas que esto acarrea, como por ejemplo que los hablantes de las provincias más densamente pobladas resultan subrepresentados y viceversa (ver cuadro 1), esto provee una “fotografía” del estado actual del léxico en la cual todas las regiones tienen un peso específico similar.
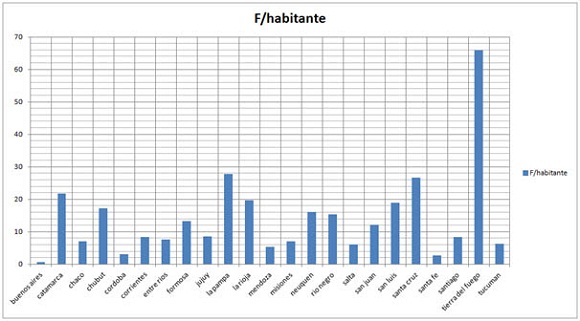
Cuadro 1. Cantidad de palabras por habitante por cada provincia. Dado que la cantidad de palabras por provincia se mantiene aproximadamente igual, las variaciones se deben a las diferencias en población, con Tierra del Fuego y Buenos Aires en los extremos.
El corpus así formado tiende hacia lo coloquial, puesto que el uso que le dan los hablantes a Twitter suele tener características conversacionales. Esto implica el intento de representar ortográficamente muchos de los rasgos de la conversación oral, como el alargamiento vocálico, los aumentos de volumen, las pronunciaciones alternativas, las onomatopeyas, la risa y demás elementos, además de vacilaciones ortográficas aleatorias. Todas estas características sumadas convierten la labor de procesar la información en un desafío complejo, puesto que la lematización (la reunión de todo un grupo de palabras bajo una forma prototípica; por ejemplo, amé, amaba, amaría, bajo el infinitivo amar) tiene que poder dar cuenta de un repertorio abierto y en expansión de recursos expresivos que los usuarios aprovechan constantemente. En relación a la labor lexicográfica, estas características convierten al corpus en una herramienta de enorme valor para la detección de coloquialismos, una categoría elusiva por definición puesto que resulta difícil, en muchos casos imposible, que lleguen a publicarse en medios escritos tradicionales.
Esta primera etapa del proyecto está usando las diferencias en el léxico de la Argentina como un primer paso para luego avanzar sobre todo el mundo hispanoparlante, en la pretensión de encontrar diferencias léxicas entre países enteros. Bajo la perspectiva de la etapa actual, por ejemplo, una palabra que se usa de manera homogénea en todas las provincias del país pero no en Chile ni en Bolivia no resulta destacada. Una vez que estén afinadas las herramientas estadísticas para determinar lo más adecuadamente posible diferencias en la extensión de uso de palabras dentro de Argentina, confiamos en que una gran parte del trabajo de ampliar la perspectiva hacia el todo el mundo hispanoparlante puede aprovecharse sin mayores modificaciones, ya que, una vez reemplazadas las coordenadas geográficas de recolección de la información, el resto del trabajo estadístico puede trasladarse con ajustes menores.
En una columna anterior, vimos que este método había servido para incorporar tres palabras que a un hablante de Buenos Aires, Río Negro o Mendoza le resultan con toda probabilidad totalmente desconocidas ( angá, angaú y mitaí). En esta ocasión, nos preguntamos qué pasa cuando la palabra forma parte del léxico general del país, pero en cierta región adoptó una acepción diferente no compartida por el resto de los hablantes. Es decir, el mismo fenómeno que palabras como bueno y amargo, ga que en la Argentina tienen, además de las generales, acepciones no compartidas por los demás hablantes de español del mundo:
bueno. 1. m. En el truco: partido que define el resultado cuando cada bando ha ganado un chico. / 2. P. ext., en otras competencias: tercer partido que define un resultado.
amargo, ga. 1. adj. coloq. despect. Sin entusiasmo ni empuje, flojo. U. t. c. s. / 2. m. Mate amargo.
Si hacemos cotejos de las listas de palabras recolectadas de una fuente, como es Twitter en este caso, comparando con listas de palabras conocidas para detectar formas novedosas o desconocidas, este tipo de contrastes pasan desapercibidos porque se trata de palabras patrimoniales que están en los diccionarios de español hace siglos. Para estos casos, una clave de que existe un uso diferenciado (y de que ese uso diferenciado puede deberse al desarrollo de una nueva acepción) son las frecuencias de uso.
Por ejemplo, la palabra manso, sa:
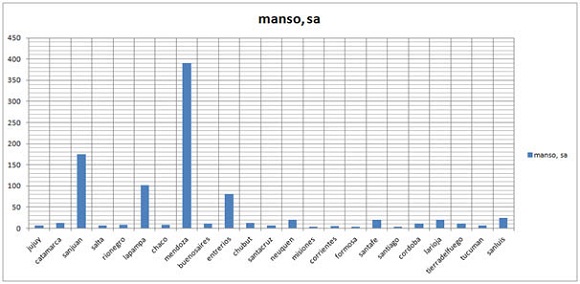
Cuadro 2. Frecuencias normalizadas de uso (apariciones cada 1 millón de palabras) para manso, sa por provincia. En Mendoza, la palabra supera cómodamente las 350 apariciones por cada millón de palabras, algo que contrasta fuertemente con el promedio de entre 10 y 25 en la mayoría de las provincias.
Estos datos, dispuestos en un mapa de la Argentina, dan la siguiente distribución:
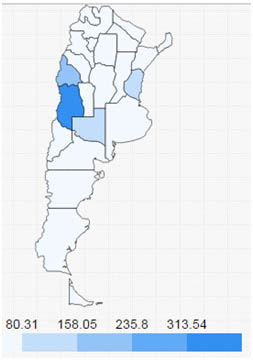
Cuadro 3. Distribución por provincias de manso, sa. Se usa en todo el territorio del país, pero solamente en ciertas provincias ese uso aumenta de manera notable.
Este patrón de uso puede dar lugar a dos hipótesis diferentes. Por un lado, puede pensarse que hay un uso muy aumentado de la palabra en sus acepciones tradicionales (acaso porque existe una actividad, como la doma, o una industria, como la ganadería, en la que se usa). La otra hipótesis es que el aumento en las frecuencias responde a que los hablantes de esas provincias desarrollaron una acepción nueva, no compartida por los demás. El siguiente paso es volver al corpus con estas dos hipótesis para ver qué dicen los datos.
Los ejemplos que devuelve la provincia de Mendoza, donde la frecuencia es más alta, revelan que se emplea como un intensificador, antepuesto en casi todos los casos, con un significado que es prácticamente opuesto al tradicional:
- Manso embole, ni el gato me habla, qué bajón.
- Manso mambo tengo con el desorden, me pone muy mal.
- Tengo manso sueño. No doy más.
- Mi mamá hace manso escándalo si le tocás alguna de sus cosas.
- Manso viaje nos comimos, qué bronca.
Este uso es coherente también con la lista de palabras a las que se antepone más frecuentemente y permite imaginar aproximadamente qué quiso comunicar el usuario en cada caso (sea el mucho aburrimiento, un mal traslado, un fuerte temor, un cansancio intenso, etc.):
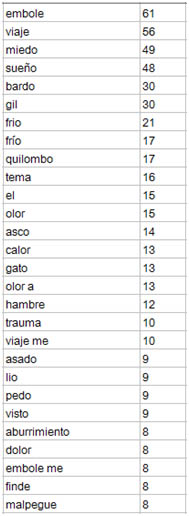
Cuadro 4. Lista de las 28 palabras a las que más frecuentemente se antepone la palabra manso en orden de mayor a menor, para la provincia de Mendoza.
De esta manera, conocer las frecuencias de uso de una palabra patrimonial en un corpus provee las herramientas para hacer la suposición informada de que existe un contraste semántico propio de una región, confirmada en este caso por los ejemplos, y para fundamentar, luego, su pertenencia al repertorio léxico de una comunidad de hablantes. Por estas razones, el DILyF propondrá a la Comisión del habla de los argentinos, compuesta por los académicos Norma Carricaburo, Antonio Requeni, Jorge Cruz y José Luis Moure, la incorporación de esta acepción en la 3ª edición del Diccionario del habla de los argentinos.